Open source · Apache-2.0
Serve AI workloads on Kubernetes.Inspect clusters from the desktop.
Two open-source projects. Krypton Runtime lets you deploy AI agents, self-hosted LLMs and MCP servers with the manifests and tooling you already use, and reach them on stable endpoints. Loupe is a desktop client for reading and operating any Kubernetes cluster.
01 / Krypton Runtime
Run AI workloads the way you run everything else.
Declare an Agent or a Model and it behaves like the rest of your cluster: the same manifests, the same kubectl, the same RBAC, the same metrics. One gateway handles agent invocation, model routing and streaming, so callers get a stable endpoint whatever is behind it.
- 01Ship an agent with one manifestBring a LangGraph, Google ADK or plain HTTP container. One
Agentresource gives it a stable endpoint, lifecycle management and scaling — no bespoke Deployment, Service and ingress per agent. - 02Self-host an LLM without a second stackPoint a
Modelat a Hugging Face GGUF file. Krypton pulls the weights and serves them, so there is no separate inference platform to run alongside Kubernetes. - 03Your OpenAI SDK, your clusterChange
base_urland existing code works unchanged against models you host:/v1/models,/v1/chat/completions,/v1/completionsand/v1/embeddings. - 04MCP servers, stdio ones tooHTTP MCP servers run as they are. Stdio binaries run behind a bundled bridge, and the operator UI lists the tools each server exposes so you can see what an agent can reach.
- 05Keep the ingress you already runThe gateway is a ClusterIP Service, so TLS, authentication and rate limiting stay where your platform team already does them — Gateway API, Nginx, Envoy or a cloud load balancer.
- 06Visible to the monitoring you haveGateway invocations, request latency, replica counts, scaler decisions and per-pod load are exported as
krypton_*Prometheus series. A starter Grafana dashboard ships in the repository.
# 1. Install the runtime
$ helm install krypton oci://ghcr.io/kryptonhq/charts/krypton \
--namespace krypton-system --create-namespace
# 2. Deploy an agent — no secrets required
$ kubectl apply -f examples/agent/python/helloworld/agent.yaml
# 3. Serve a GGUF model from Hugging Face
$ kubectl apply -f config/samples/llm/qwen2.5-0.5b.yaml
# 4. Call the model through the OpenAI-compatible API
$ curl localhost:8080/v1/chat/completions \
-d '{"model":"qwen2-0-5b","messages":[…]}'Chart installation, an agent, a model, and a chat completion request routed through the gateway.
02 / Loupe
A desktop client for Kubernetes.
Open it, pick a context, and you are looking at your cluster. Loupe uses the kubeconfig you already have, so there is nothing to install in the cluster, no account to create and no telemetry. Native builds for macOS, Linux and Windows.
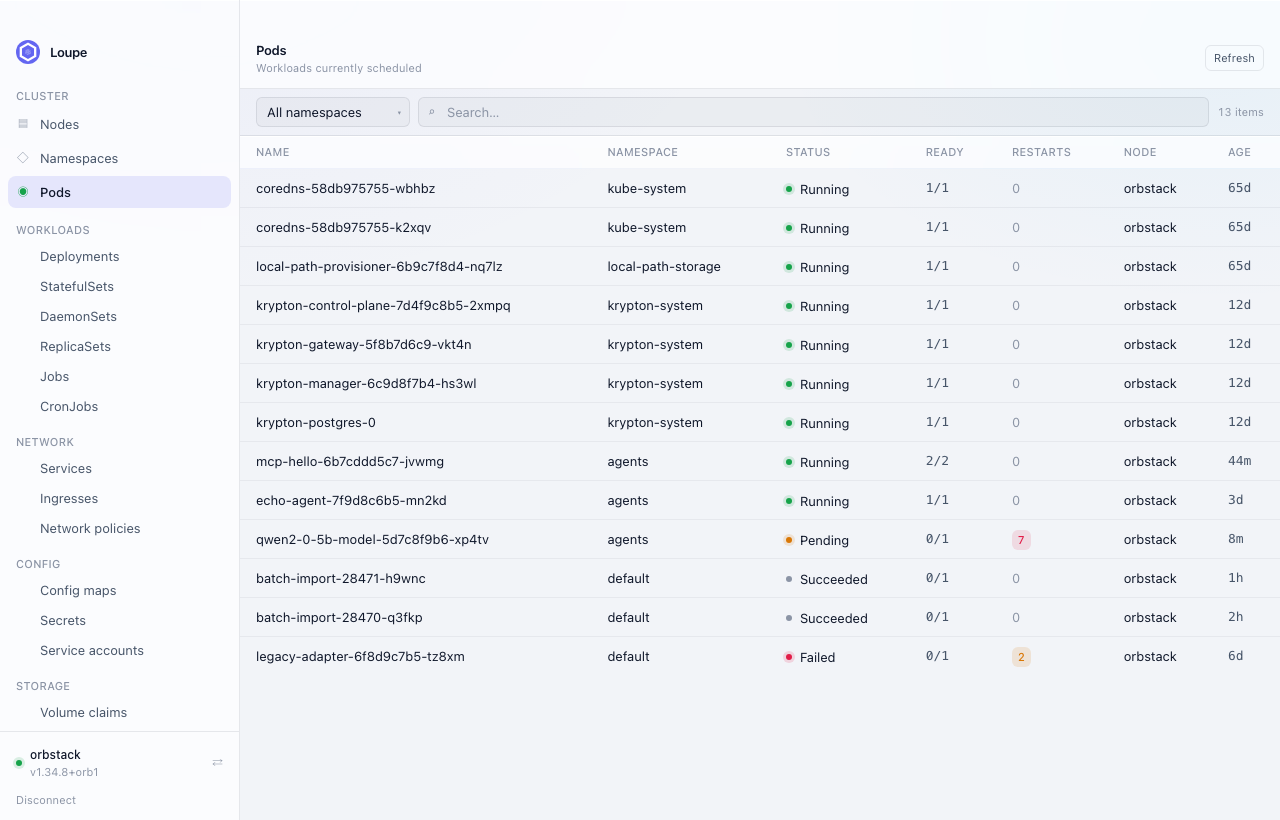
- 01Every context, one switch awayYour kubeconfig contexts are all there on launch. Move between a local kind cluster and production without reconnecting, re-authenticating or opening a second window.
- 02Your CRDs, not just the built-in kindsCustom resources sit alongside deployments and pods, with the columns their authors defined. Install a CRD today and browse it today — no Loupe release required.
- 03Answers on the detail pageWhy a pod is crash-looping, how much CPU a node has actually committed, which finalizer is holding a namespace in
Terminating— without going back to the terminal. - 04Helm releases without the CLIValues, rendered manifests, notes and the full revision history for every release in the cluster — no
helmbinary and no scrolling back throughhelm history. - 05Logs, including the container that diedStream live with container selection and timestamps, or read the previous container’s logs to find out what killed it.